arms前端监控源码全方位分析
本文记录关于 arms - 前端监控调研时发现的问题和思考。
关于日志公共字段
一、关于 page 字段
page 字段用于标识当前页面的 pageid。当未开启 SPA 自动解析时,page 字段均能够正常记录,然而当开启 spa 自动解析功能时,奇怪的现象发生了,第一个页面的日志的 page 字段无法正常获取而是被设置成默认值“[index]”(但是 pref 日志不会被影响),后续页面切换的日志能够正常显示。
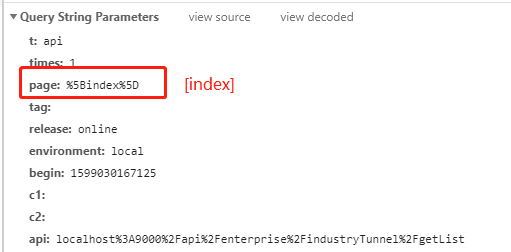
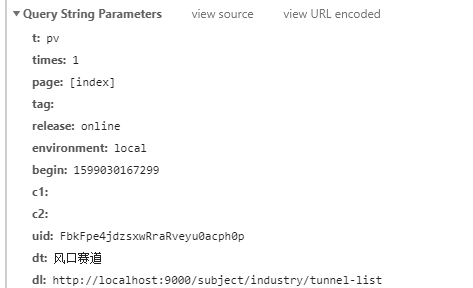
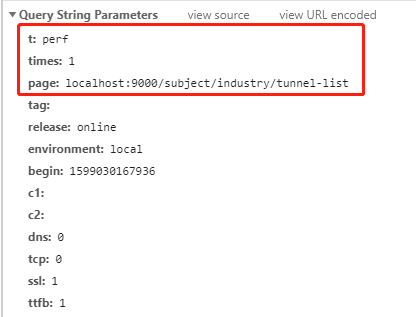
当前端页面路由切换时 page 字段又能够正常获取了:
原因分析:先看下官方给出的源码。
1 | |
框架只会解析 hash 部分,即#号后面的部分,但我们的项目是使用 vue 的 history 模式开发的,所以无法解析。但这无法解释为什么后面的页面又能够正常获取 page 字段的原因。我们通过断点调试源码进一步进行分析,发现 parseHash 的逻辑实际上是这样的:
1 | |
发现是否能获取到 page 字段关键在于参数“e”,而第一次进入页面时该值为空:

而在页面切换时该值为当前页面路径:

继续排查该参数的来源,我们知道当 vue 使用 history 模式时,页面的切换事件捕获时依靠 historystatechange 来获取的,arms 也是使用这一事件进行捕获,源码如下:
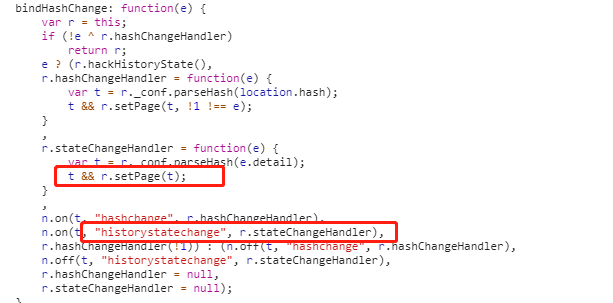
我们发现只有当捕获到 historystatechange 事件后框架才会设置 page 字段,而第一次页面加载时不会触发这个事件的,所以导致无法正确获取 page 字段,这应该算是框架设计上的一个缺陷。
那么如何修复这个问题,官方提供了自定义 parseHash 函数来实现自定义 pageid 的功能:
1 | |
然而这并不能解决第一次获取失败的问题,即使考虑到时序的问题,在初始化后直接调用 setConfig,但测试结果依旧无法生效:
1 | |
后测试只有在初始化时直接设置才能够解决,说明 setConfig 方法本身也是异步执行的:
1 | |
思考:
pages 作为日志追踪的重要参考字段,其准确性是非常重要的,arms 在设计这个字段的默认获取方式上存在一定的缺陷,不过好在可以通过自定义配置的方法弥补。
二、关于自定义字段
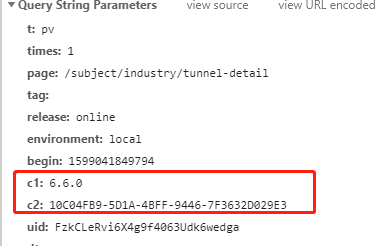
arms 提供了 c1/c2/c3 三个自定义字段供用户使用,可以对日志的字段进行扩展。例如客户端内的场景就可以对用户的 APP 版本,设备号等字段进行上报,可以直接在后台进行筛选。
关于 API 日志
一、上报字段格式
arms 的 api 上报有着自己的一套解析规范,参考源码如下:
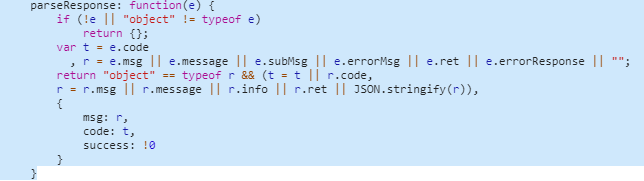
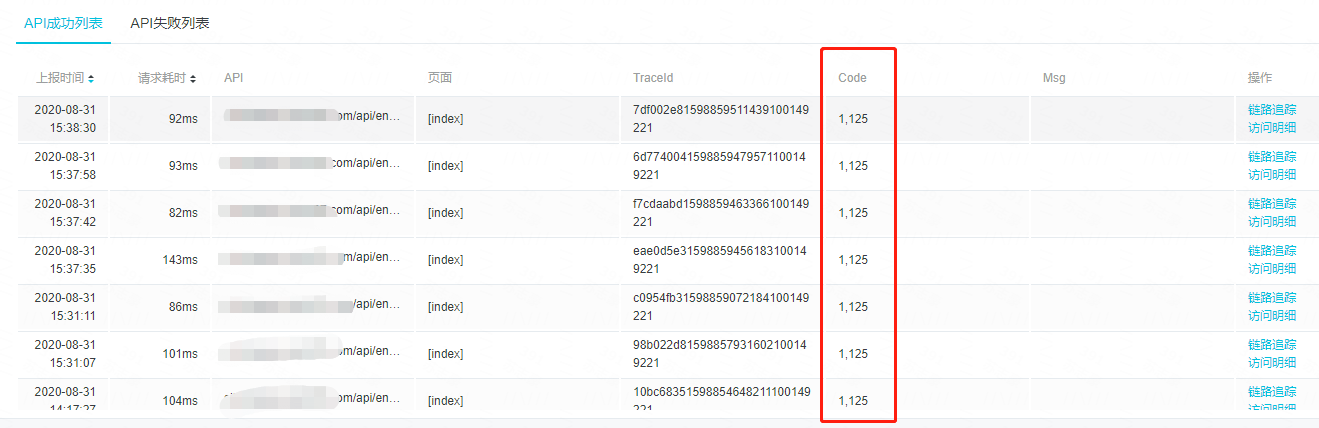
当接口状态为“success”的时候,框架会优先解析 response 字段,提取出 code 和 message 相关的字段上报,所以当我们的业务接口中有返回类似的字段时,会被框架误认为是接口是否成功的相关信息被上传上去,例如下图就是把接口里面的“code”字段误认为 http 请求的 code 展示了

至于他如何判断接口状态,我们看这一段源码:

可见成功和失败是通过 http 状态码判断的,然后 code 和 message 字段是由接口业务决定的,这么设计可以让 api 日志的维度更加丰富,但同时对接口返回值的格式也有了一定的要求。
思考:
API 日志的上报机制从侧面反映了 arms 团队对接口定义的规范的重视,通过 http 状态码,业务状态码,业务 message 三个字段来定义一个接口的返回情况。
很遗憾目前我们的前后端接口定义还不是很规范,所以这个功能对于我们目前的业务来说有点鸡肋。flogger(我自研的一款前端性能收集工具) 采用的方式是将 responseText 全部上报上来(做了超长截取),在目前的情况下也能够解决大部分问题,但是上传上来的字段仅仅只能做排查具体问题的参考而已,例如用户反馈。由于没有结构化,所以没办法进行更进一步地分析和归类,也没办法制作各种可视化图表。
二、请求拦截方式
先上源码:
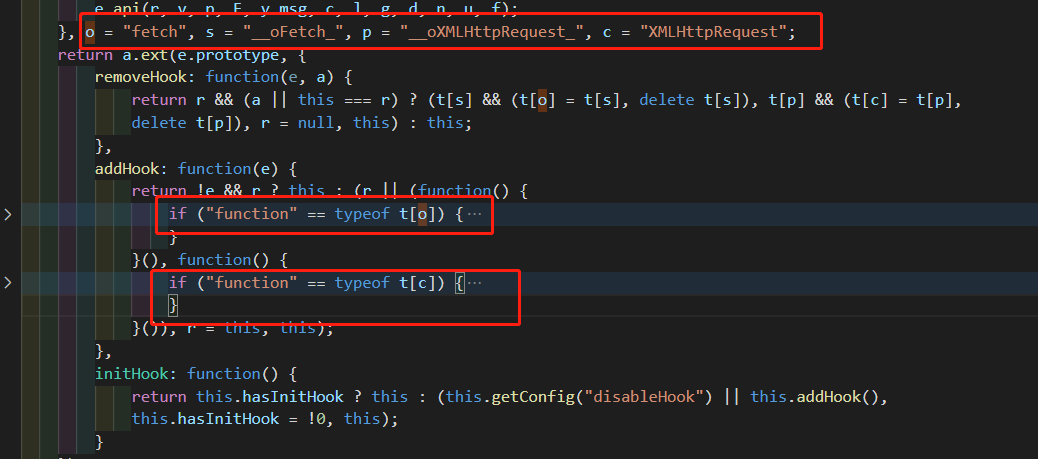
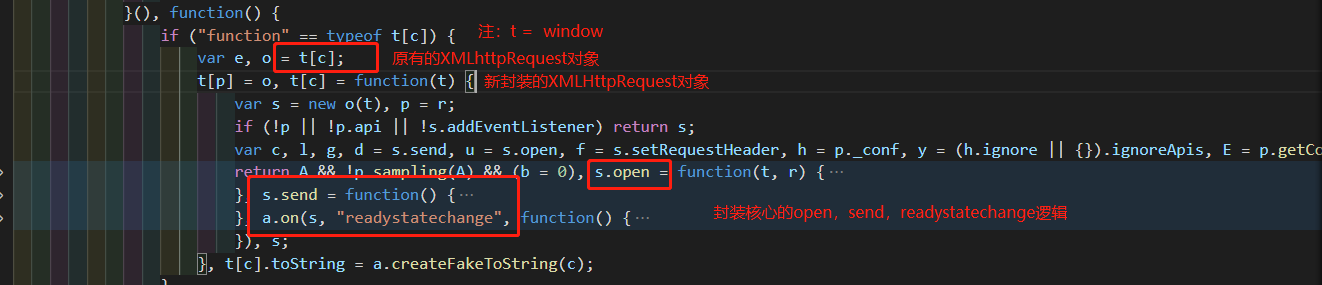
目前主流的前端请求数据的方式为两种:fetch 和 ajax。ARMS 团队通过将原生方法写入到另一个全局变量中,再重新封装一个新的 fetch 对象和 XMLHttpRequest 对象实现请求拦截。好处是不会过多依赖原生方法,只要原生方法上有 open 等核心方法即可实现(避免被第三方库干扰),缺点是由于是重新分装的对象,其原型链上丢失了原本 XMLHttpRequest 对象上的属性,会对其他库造成影响。
flogger 中没有实现对 fetch 的封装(目前我们没有使用到 fetch api),而对于 XMLHttpRequest 的拦截是采用直接修改原型链的方式,更加简单粗暴。好处是不会影响原生对象上(包括原型链上)原有的属性。缺点是比较依赖原生 XMLHttpRequest 原型链上的方法,如果 XMLHttpRequest 原型链被修改则无法实现。所以当 arms 和 flogger 一起使用的使用会发现 flogger 无法正常拦截请求了。。。
思考:
arms 和 flogger 在设计拦截方式的整体思路上有差别。arms 通过减少对其他 API 的依赖,只使用核心方法,优先保证自己的功能可用,但对原有的 API 具有破坏性,可能会造成其他框架无法使用。ARMS 作为一款阿里对外收费的产品,首先保证自己逻辑可用肯定是最重要的,这么设计也是无可厚非。
flogger 可以参考 arms 的设计对实现方式进行调整,但可以在此基础上进一步优化,将原生方法中的属性尽可能继承下来。参考文章:https://www.cnblogs.com/ranyonsue/p/11201730.html
关于接入方式
arms 提供了三种不同的接入方式,分别是:
异步加载:又称为非阻塞加载,表示浏览器在下载执行 JS 之后还会继续处理后续页面。若对页面性能的要求非常高,建议使用此方式。注意:由于是异步加载,ARMS 无法捕捉到监控 SDK 加载初始化完成之前的 JS 错误和资源加载错误。

从接入方式可以看到逻辑是先通过同步 js 代码在 window 上写入一个全局变量 __bl,其中有一个 config 属性配置了初始化配置,然后异步加载一个 js 代码,当加载成功后会重写全局变量 __bl,添加 setConfig(),api()等 api。使用这种方式接入最为方便且不会影响页面性能。缺点是由于 sdk 是异步加载的,当 sdk 加载成功前无法获取错误信息和接口信息,并且没办法使用 setConfig 等 api 进行配置。
同步加载:又称为阻塞加载,表示当前 JS 加载完毕后才会进行后续处理。如需捕捉从页面打开到关闭的整个过程中的 JS 错误和资源加载错误,建议使用此方式。

从源码来看该方案会阻塞浏览器 dom 解析,对性能会造成影响,不建议使用这种方式。
NPM 包:可减少页面加载的 Script 数量,且您可以控制页面 Script 的 CDN,以及将前端监控作为单独的模块处理。
该种方式将 sdk 和业务代码打包到一起去,由于业务代码是异步加载的,所以还是属于异步加载的情况,但是可以通过代码逻辑保证 sdk 优先于业务代码执行,避免了异步加载方式无法使用 api 的问题,建议采用此方案。此方案唯一的缺点是若业务代码打包时存在 bug 导致 js 报错,有可能导致 sdk 也无法正常启动,没办法记录到相关的错误。